

Anthropic brengt Fable 5 uit en bouwt de paywall alvast mee
Fable 5 is hetzelfde model als Mythos 5, maar met ingebouwde grenzen. Tot 22 juni is het gratis, daarna betaal je per gebruik.


De afgelopen dagen liet ik Fable 5 los op mijn eigen repo’s. Code reviews in de breedste zin, dus ook mijn workflows en agent-flows, met als opdracht om gaten te spotten. Hij vond dingen die eerdere modellen lieten liggen. Tegelijk hou ik een slag om de arm, want ik weet nog niet of dat aan het model ligt of aan de context en de prompt waarmee ik hem voedde. Wat me meer bezighoudt, is de timing. Anthropic geeft zijn sterkste model ooit vrij, vier dagen nadat het opriep tot een wereldwijde AI-pauze en hetzelfde model blijft onder een tweede naam alsnog achter slot. Jij hebt twee weken om het gratis uit te proberen.
Het slot zit niet meer op de deur, maar in het model
Even terugspoelen naar april. Anthropic hield zijn sterkste model, Claude Mythos Preview, toen bewust achter een muur. Alleen cyberdefenders en infrastructuurpartijen mochten erbij via Project Glasswing, een samenwerking met de Amerikaanse overheid. In de editie “Het sterkste code-model ter wereld is Chinees, gratis en open source” schreef ik dat Anthropic als enige groot lab zijn frontier vasthield terwijl de rest gewoon uitbracht.
Die muur bestaat nog steeds, alleen staat hij ergens anders. Fable 5 en Mythos 5 zijn namelijk hetzelfde model, met dezelfde weights. Het verschil zit in drie classifiers, aparte AI-systemen die met je verzoek meekijken. Gaat je vraag over cybersecurity, biologie en chemie, of lijkt het op een poging om het model leeg te trekken voor het trainen van een concurrent (distillatie), dan neemt Opus 4.8 het antwoord over en krijg je daar een melding van. Dat gebeurt in minder dan 5 procent van de sessies. Net als bij de zelfscankassa eigenlijk. Je scant alles zelf, maar bij de fles wijn gaat het lampje branden en komt er een medewerker kijken. De winkel is open voor iedereen, de controle zit op het schap.
En de capaciteiten liegen er niet om. Op SWE-bench Verified scoort Fable 5 95 procent, waar Opus 4.8 op 88,6 blijft steken en Gemini 3.1 Pro op 80,6. Op de zwaardere SWE-bench Pro is de voorsprong elf punten op Opus en ruim twintig op GPT-5.5. Voor mij voelt deze sprong als Opus 4.5 afgelopen november en dat was de laatste keer dat een release als vooruitgang aanvoelde. Ik ben niet de enige, want die vergelijking met 4.5 viel deze week vaker. Hoe langer en complexer de taak, hoe groter het verschil met alles ervoor.
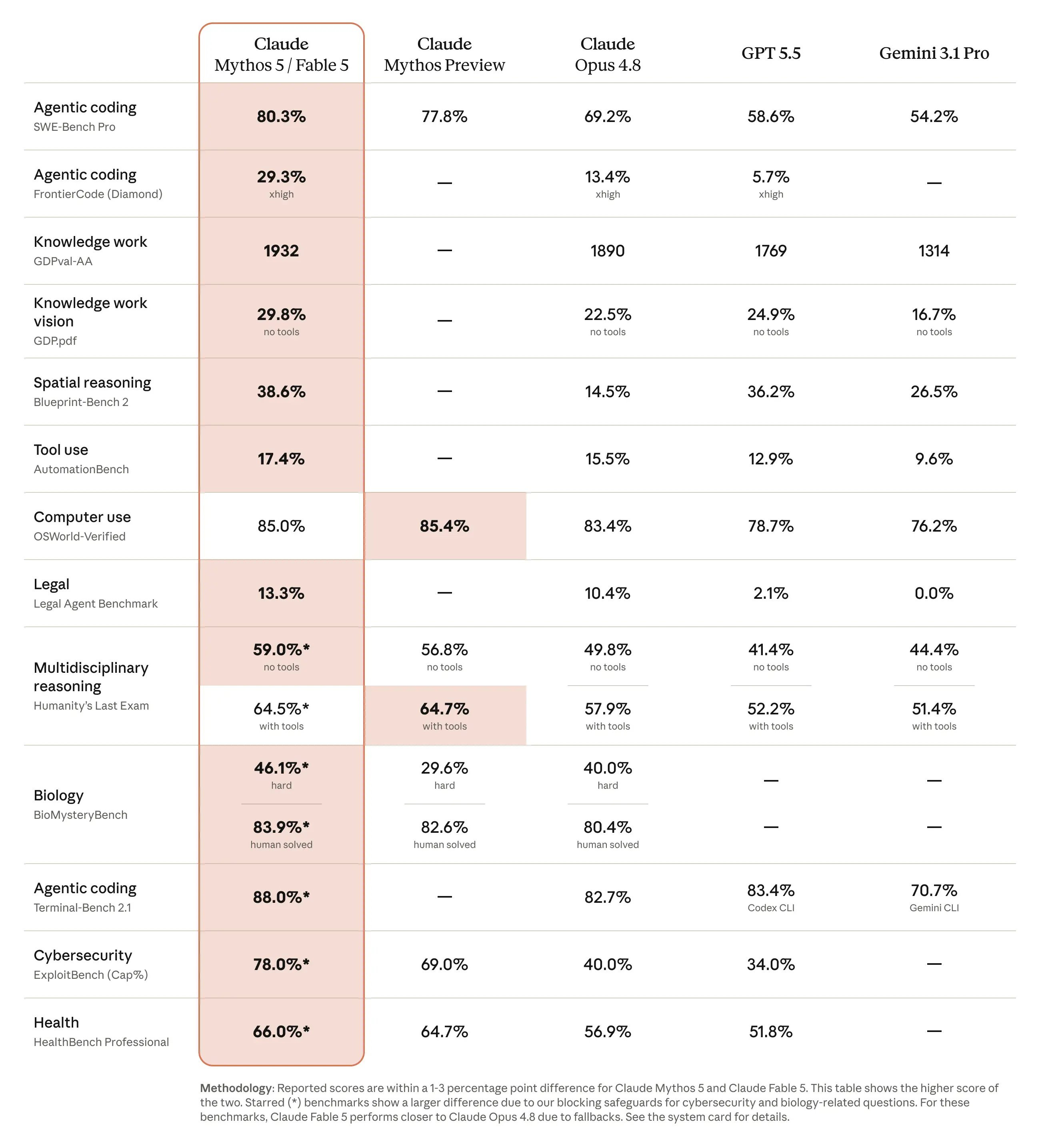
Wie bepaalt welk model jij krijgt
Op papier is die fallback netjes opgelost. Je krijgt een melding en Opus 4.8 is op zichzelf een uitstekend model. Toch wringt hier iets, want het model bepaalt voortaan wanneer jij de mindere goden voorgeschoteld krijgt.
In de system card staat bovendien een subtielere variant. Wordt Fable 5 ingezet voor frontier-AI-ontwikkelwerk, denk aan pretraining-pipelines of trainingsinfrastructuur, dan beperkt het model stilletjes zijn eigen effectiviteit, zonder melding. Volgens Anthropic raakt dit ongeveer 0,03 procent van al het verkeer. Dat klinkt als een voetnoot. Voor mij is dit het belangrijkste uit de system card, want hier staat een model dat in strategisch gevoelige domeinen bewust minder zijn best doet en jou dat niet vertelt.

Ik wil in controle zijn over welk model mijn werk doet. In controle zijn betekent bewuste keuzes maken en die keuzes maak ik niet voor niets. OpenAI probeerde dit soort automatische routing bij de lancering van GPT-5 en dat liep in het begin volledig in de soep. Voor het grote publiek snap ik de gedachte, het zware model is voor de meeste vragen overbodig en routing bespaart iedereen kosten. Voor professioneel werk werkt het precies andersom. Als ik Fable kies, wil ik Fable.
Voor de meeste lezers blijft dit overigens theorie, want in ruim 95 procent van de sessies merk je er niets van. En wie in security werkt moet weten dat Fable op cybertaken bewust op Opus-niveau presteert. Daar doen de classifiers gewoon hun werk.
Eerst de pauzeknop, dan de beursgang
Op 5 juni riep Anthropic op tot een wereldwijde pauze in AI-ontwikkeling en medeoprichter Jack Clark zei bij de BBC dat AI een rempedaal nodig heeft. Vier dagen later brengen ze het krachtigste model ooit uit, ruim een week na hun eigen beursaanvraag. Ondertussen draaide Mythos intern al maanden mee.

Ik kan daar maar één ding van maken. Dit is marketing in aanloop naar de beursgang. Er zit een kern van waarheid in, want het model is sterk en een adempauze zou onderzoekers lucht geven. Tegelijkertijd schreeuwt half Washington van de daken dat China nooit sterkere modellen mag krijgen en een pauze bereikt precies het tegenovergestelde. Voor het publiek zeggen ze het een, feitelijk en politiek doen ze het ander.
En die gratis periode tot 22 juni is in dat licht ook geen toeval. Niets laat beleggers zo mooi zien hoe groot de vraag is als twee weken waarin iedereen tegelijk je duurste model mag aanzetten.
Negenenhalf uur werk uit één opdracht
Het meest veelzeggende voorbeeld komt van onderzoeker Ethan Mollick, die het model vroeg mocht testen. Hij stopte een ontwerpdocument van 19 pagina’s in het model en kwam terug bij software die af was. Fable werkte er negenenhalf uur autonoom aan, startte eigen subagents op voor research en verificatie en maakte onderweg honderden kleine keuzes waar geen mens naar heeft gekeken. Zijn rol verschoof van uitvoerder naar opdrachtgever. Net als bij een architectenbureau. Je beschrijft wat je wilt, je betaalt en je beoordeelt het eindresultaat zonder ooit op de werkvloer te komen.
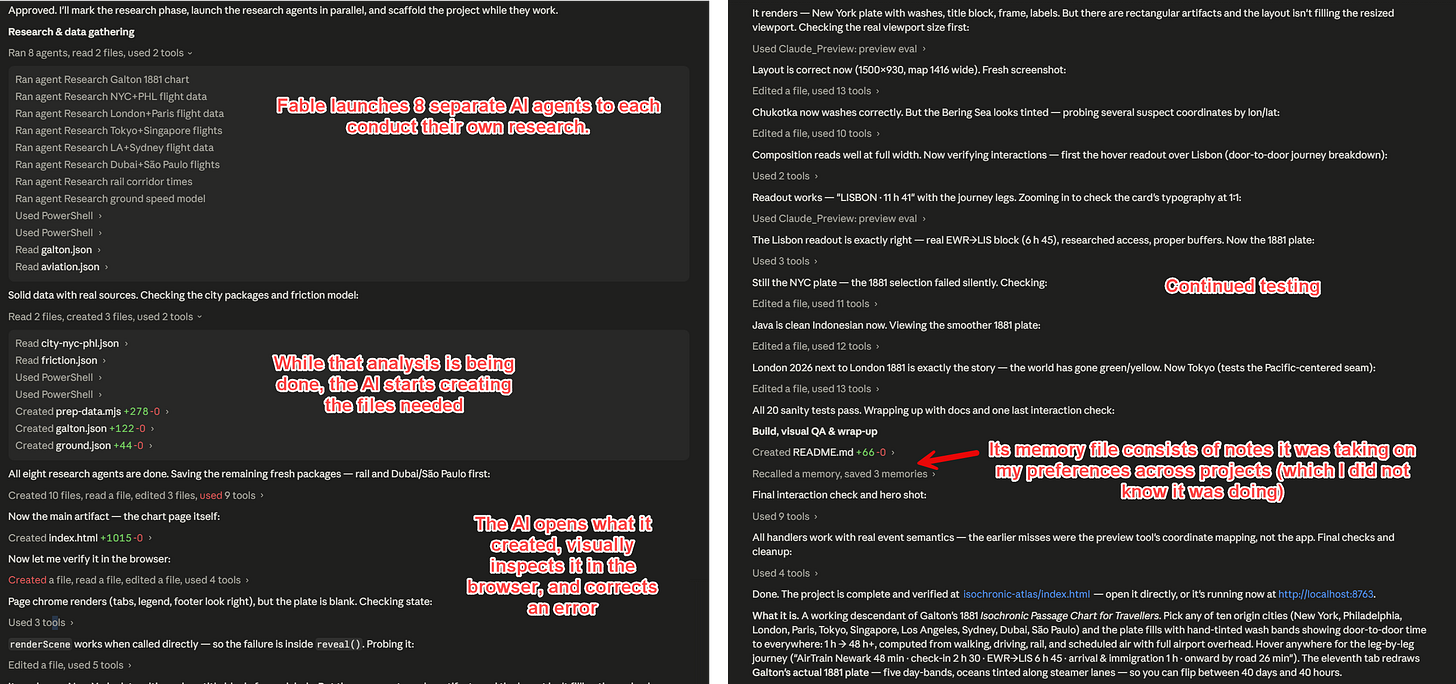
Stripe zag tijdens de eerste tests hetzelfde patroon op productieschaal. In een Ruby-codebase van 50 miljoen regels voerde het model in één dag een migratie uit waar een heel team anders ruim twee maanden over zou doen.
Het Claude Code-team van Anthropic vat het mooi samen. Vroeger controleerden ze of het model het werk goed had gedaan, nu controleren ze of het model het juiste werk doet. Wie ooit een workshop van mij volgde herkent hier Plan-Do-Check in. De do-fase schuift naar het model en jouw waarde verschuift naar de plan-fase en de check-fase. Daar zit straks je vak.
En dan de andere kant, want die is er ook. Testers melden dat Fable vaak veel te compacte en zware teksten schrijft, waardoor ze het model herhaaldelijk moesten vragen om simpeler uit te leggen. One-shot design is zwak en vraag je om een MVP, dan krijg je iets heel minimaals. Het model stelt bovendien eindeloos verduidelijkingsvragen voordat het gaat bouwen. Voor teksten, specs en strategiewerk pak je dus gewoon Sonnet of Opus. Daar komt mijn eigen kanttekening bij. Bij elke modelrelease is er één hype-usecase die opeens heel goed werkt. Eerst was het SVG’s one-shotten, daarna complete websites, nu 3D-werelden. Ik heb het zelf geprobeerd en ja, het werkt verbluffend. Maar goed, dat zegt iets over de demo, nog weinig over jouw werkweek.
Gratis tot 22 juni, daarna usage credits
Fable 5 kost via de API 10 dollar per miljoen input-tokens en 50 dollar per miljoen output-tokens, exact het dubbele van Opus 4.8. Daar komt bij dat de nieuwe tokenizer dezelfde tekst in ongeveer 30 procent meer tokens uitdrukt dan de oudere Claude-modellen en dat de eerste testers ruwweg twee keer zo snel door hun limieten heen zijn. Wie de editie over de ontploffende AI-rekening nog vers heeft, weet waar dit heen gaat.
In de abonnementen zit een addertje met een datum. Tot en met 22 juni zit Fable 5 gratis in Pro, Max, Team en Enterprise. Op 23 juni gaat hij eruit en betaal je per gebruik met usage credits. Anthropic belooft hem terug te brengen in de abonnementen zodra de capaciteit het toelaat en daar staat geen datum bij.

Dit baart me meer zorgen dan de prijs zelf. Concurrentie houdt de prijzen in deze markt laag. Amerikaanse labs kunnen geen abonnementen van tienduizend euro vragen zolang Chinese en open source modellen in de buurt blijven. Valt die concurrentie weg, dan gaan we richting absurde lock-ins en prijzen.
Voor corporate lezers nog een belangrijk detail. Op Mythos-klasse modellen geldt verplichte dataretentie van 30 dagen, ook als je via AWS of Google Cloud werkt en zero data retention is er voor deze modellen dus niet bij. Anthropic gebruikt de data naar eigen zeggen alleen voor veiligheid, logt elke menselijke toegang en verwijdert na 30 dagen. Of dat binnen jouw risk appetite en compliance past, is een gesprek met je privacy officer waard voordat je dit model op klantdata zet.
Twee weken om het zelf te voelen
Dus, mijn advies. Probeer het nu, juist omdat het tot 22 juni in je abonnement zit. Geef het je moeilijkste werk, zoals een hardnekkig debugging-probleem, een documentzware analyse of een review van je complete werkproces zoals ik deed. Begin op een laag effort-niveau, dat is voor de meeste taken al genoeg en bewaar de hoogste stand voor je zwaarste denkwerk. Houd Sonnet en Opus in je rotatie voor dagelijks werk en teksten.

En raak er niet te gewend aan, want voor je het weet verdwijnt dit achter een hogere paywall. Ik zou zeggen, pak die twee weken. Dan weet je straks in ieder geval uit eerste hand wat er al die tijd achter de muur lag.
Ook het vermelden waard
OpenAI dient in stilte zijn beursaanvraag in Ruim een week na Anthropic heeft ook OpenAI vertrouwelijk een S-1 ingediend bij de SEC. Op secundaire markten is Anthropic OpenAI inmiddels voorbij in waardering. De twee grootste AI-labs racen tegelijk naar de beurs en dat verklaart veel van het marketinggeweld in deze editie.
De nieuwe Siri draait op Gemini Apple presenteerde op WWDC een vernieuwde Siri, gebouwd op Apple Foundation Models die samen met Google op Gemini-technologie zijn ontwikkeld, on-device en via Private Cloud Compute. Siri krijgt een eigen app en cross-app context. Het was ook de laatste WWDC van Tim Cook, die per 1 september wordt opgevolgd door John Ternus.
Duitse rechter maakt Google aansprakelijk voor AI Overviews De rechtbank in München oordeelde dat AI-samenvattingen Googles eigen woorden zijn, waardoor de bescherming als doorgeefluik vervalt. Google mag via AI Overviews geen onjuiste claims meer verspreiden over twee Duitse uitgevers. Een precedent voor iedereen die generatieve AI-output publiceert.
ING laat AI hypotheekaanvragen meebeoordelen ING zet als eerste grote Nederlandse bank AI in bij het beoordelen van afwijkende hypotheekaanvragen en dat is tachtig procent van alle aanvragen. Een mens neemt nog steeds de eindbeslissing, met het AI-advies ernaast. AI-praktijk dichtbij huis dus, inclusief de bekende bias-discussie.
Microsofts open source tools gehackt om AI-developers te bestelen Hackers injecteerden malware in tientallen Microsoft-repos op GitHub, gericht op tools die developers gebruiken met Claude Code, Gemini CLI en VS Code. Minstens 70 projecten gingen offline. Wie met AI-coding tools werkt, wil zijn dependencies deze week even nalopen.
Lees ook
De scheidsrechter heeft een AI-assistent. Japan, Zweden en Tunesië ook.
NVIDIA wil de AI-cloud onder je bureau zetten
Vind je dit waardevol? Deel het.
Stuur THE HUMAN LOOP door naar één collega die ook met AI bezig is. Voor elke vriend die zich aanmeldt, krijg je gratis maanden premium: inclusief alle Playbooks.
Concreet:
2 vrienden = 1 maand.
5 vrienden = 3 maanden.
12 vrienden = een half jaar.