

Het sterkste code-model ter wereld is Chinees, gratis en open source
Anthropic verbergt Mythos. OpenAI kilde Sora. Ondertussen zet China zijn sterkste modellen gewoon op HuggingFace.

Even een huishoudelijke mededeling

Twee dingen die ik even wil delen.
De nieuwsbrief heeft een nieuwe jas en een nieuw adres, thehumanloop.nl. Makkelijker te onthouden, makkelijker te delen, en het past beter bij waar deze nieuwsbrief inmiddels in uitgegroeid is. Sinds ik begon te schrijven is het publiek hard gegroeid en komen er elke week meer abonnees bij en nieuwe vragen binnen. Dank aan iedereen die leest, reageert en verder deelt!
Het tweede is groter. Het bedrijf waar deze nieuwsbrief uit voortkomt heet niet meer HUMANAGENT. Mijn AI-consultancy uit Rotterdam, opgericht in november 2022, is sinds dit voorjaar samengevoegd met het IT-recruitmentbureau van mijn compagnon Seleman uit Capelle aan den IJssel. Twee aparte bedrijven, twee aparte kantoren, en bij elke klant precies hetzelfde patroon. Ze hadden tegelijk begeleiding nodig, training nodig en talent nodig, en moesten daarvoor bij twee verschillende bureaus langs. Wij dachten al een tijdje dat het anders kon. Dus hebben we de boel samengevoegd.
De nieuwe naam is WAINUT, uit te spreken als why not. Die houding zit bewust in de naam, want zo helpen we organisaties ook. Als AI goed wordt ingezet, is er geen reden om niet vooruit te gaan. Tien specialisten, één team, drie diensten onder één dak. AI Consulting, AI Training en AI Staffing. Te vinden op wainut.ai.
Zo, dat wilde ik even kwijt. Champagneglas in de hand en door naar de inhoud.
De video die alles verraadt
Om WAINUT te introduceren hebben we zelf een leuke videotrailer gemaakt. Hieronder, kijk hem en dan praten we verder.
Klaar? Goed. Nu de onthulling waar dit artikel over gaat.
Het model waarmee we die video hebben gemaakt heet Seedance 2.0. Het is Chinees. Gebouwd door ByteDance, het moederbedrijf van TikTok. En ik kon het gewoon gebruiken. Via een gewone marketplace, met een gewone Europese creditcard, zonder whitelist of wachtlijst of bedrijfs-NDA. Je opent het, je voedt het je prompts, je krijgt je shots terug. Hollywood noemde het eerder dit jaar “hyperrealistisch” en probeerde het tegen te houden via copyright-claims. Dat is in wezen het grootste compliment dat zo’n model kan krijgen.
En dat brengt me bij iets wat ik de afgelopen week steeds vaker tegenkwam.
De richting is omgekeerd

In dezelfde week dat ik met Seedance 2.0 die trailer voor WAINUT bouwde, gebeurden er drie andere dingen in de AI-wereld. Samen laten ze een patroon zien.
Anthropic kondigde Claude Mythos aan. Hun sterkste model tot nu toe. Niet voor jou en mij. Niet voor hun vaste klanten. Niet voor hun betaalde abonnees. Mythos ging alleen naar een consortium van ongeveer veertig grote bedrijven. Amazon, Apple, Microsoft, Cisco, Broadcom, Palo Alto Networks, JP Morgan, de Linux Foundation. Scott Bessent, de Amerikaanse minister van Financiën, trommelde meteen daarna de CEO’s van de grootste Amerikaanse banken bijeen. Fed-voorzitter Powell zat ook aan tafel. Waarom? Omdat Mythos in staat zou zijn om duizenden onbekende beveiligingslekken te vinden in bijna elke software die de wereld draait, en dat is volgens Anthropic te gevaarlijk om publiek te maken. Er is daar ook felle kritiek op, ook in de internationale pers, die het framing-theater noemt richting een aankomende IPO. Maar het punt voor nu is simpeler. Mythos is er, en jij kan er niet bij.
OpenAI deed iets anders. Ze killden Sora. De consumer-videoapp waarvan Sam Altman een paar maanden geleden nog zei dat het hun “tweede ChatGPT-moment” zou worden. Disney had net een miljardendeal getekend om Marvel-, Pixar- en Star Wars-personages beschikbaar te stellen. En toen trok Altman alsnog de stekker eruit. De cijfers uit gelekte interne communicatie zijn pijnlijk duidelijk. Sora verbrandde ongeveer vijftien miljoen dollar per dag aan rekenkracht, tegenover zo’n twee miljoen omzet. En die compute was hard nodig voor Spud, een nieuw intern model waar OpenAI al weken aan bouwde. Disney’s miljard verdampte, de licentiedeal is dood, het enterprise-pilot-programma is dood, Sora zelf is dood.
Apart bekeken is alles wat hierboven staat verdedigbaar. Samen vormen ze een beweging. De Amerikaanse toplabs trekken zich terug achter muren. Ze doen dat om verschillende redenen tegelijk (IPO-druk, compute-schaarste, reputatiemanagement, security-framing) en al die redenen kunnen legitiem zijn. Maar wat je als gebruiker ervaart is dit. De sterkste modellen zijn steeds moeilijker bereikbaar. De publieke versies worden duurder. De frontier verdwijnt naar binnen.
Iemand die dit precies zag aankomen was Ilya Sutskever, oud-chief-scientist van OpenAI en oprichter van Safe Superintelligence. Eind november zat hij bij de podcasthost Dwarkesh Patel aan tafel en voorspelde dat AI-labs van een “het maakt fouten”-houding zouden schakelen naar wat hij letterlijk een paranoia-modus noemde, zodra de capaciteiten daar de aanleiding voor gaven. Vier maanden later staat Mythos achter slot en houdt OpenAI Spud intern. De korte clip hieronder is wat mij betreft een aanrader om even bij stil te staan.
Wat er in Shenzhen gebeurt
Op hetzelfde moment rollen Chinese labs de deur open.

In februari bracht ByteDance Seedance 2.0 uit. Hollywood sloeg alarm, de rollout werd even gepauzeerd door copyright-drama, en in maart kwam het model terug via CapCut en een directe API. Het werkt in Europa, jullie hebben mijn filmpje hierboven gezien.
In dezelfde maand lanceerde Kuaishou (nog zo’n Chinese reus, eigenaar van de TikTok-concurrent Kwai) Kling 3.0. Native 4K, vijftien seconden per shot, audio meegegenereerd in meerdere talen en dialecten. Ook direct beschikbaar in de Europese markt, ook via een gewone creditcard.
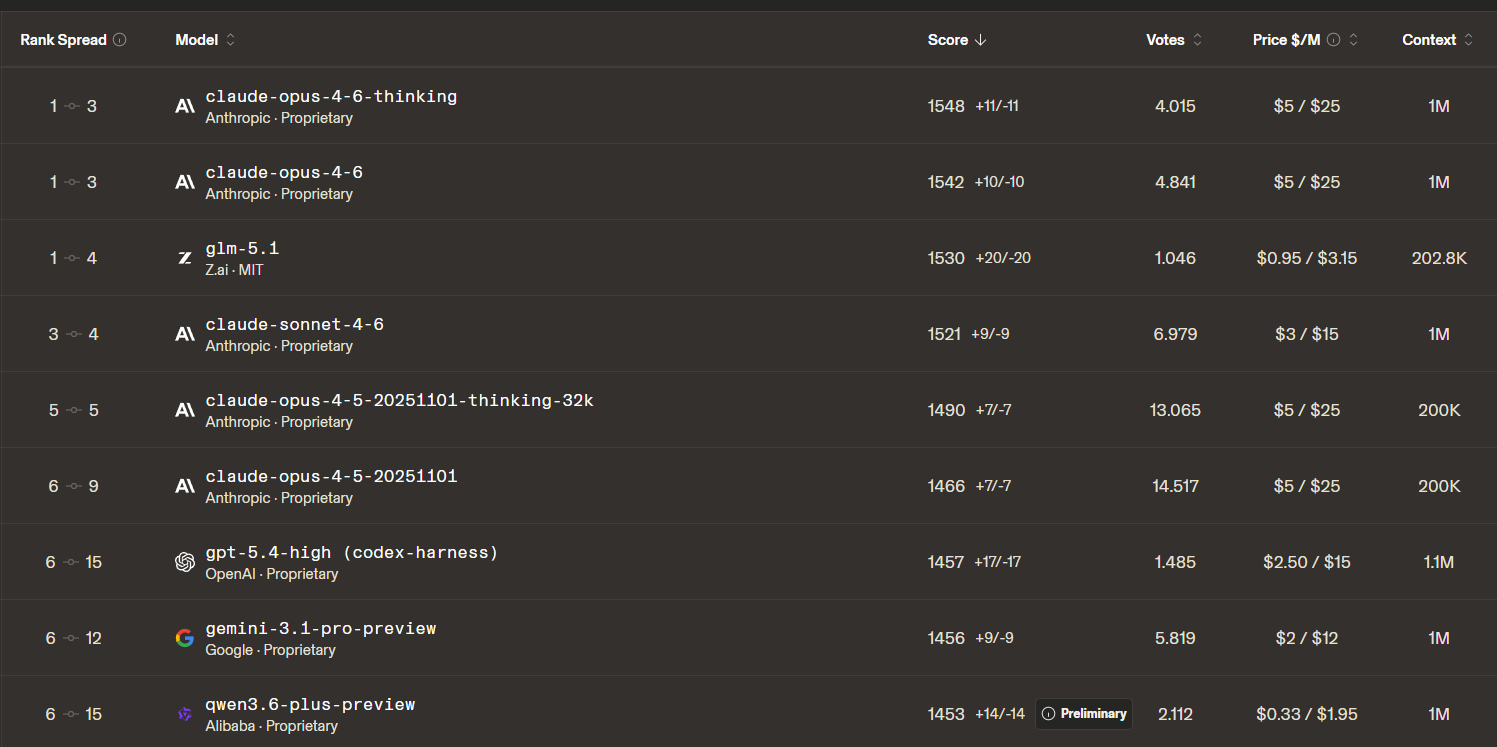
In april volgde Z.ai met GLM 5.1, een code-model. En het gaat hier ook niet om “een beetje beter”. GLM 5.1 staat op SWE-Bench Pro, een van de zwaarste benchmarks voor software-engineering, op nummer 1 in de wereld. Boven Claude Opus 4.6, boven GPT 5.4, boven alles wat Silicon Valley aanbiedt. Op Code Arena staat het op plek drie volgens de mean Elo, maar de rank spread loopt van 1 tot 4. Statistisch zit het dus in dezelfde top-tier als de twee Opus-varianten erboven. Eerste open-weights model dat ooit zo hoog komt. En voor wie de prijs erbij rekent, slaat het verhaal helemaal door. GLM 5.1 kost een fractie van wat Opus 4.6 per token vraagt, dus per euro aan output verslaat het Sonnet 4.6, Opus 4.5 en GPT-5.4 met flinke marge. MIT-licentie, gewichten op HuggingFace, gratis te downloaden.
Minimax, eveneens een Chinees lab, bracht in diezelfde week M2.7 uit. Een agent-model dat zichzelf deels heeft helpen ontwikkelen. Minimax zette een scaffold op, gaf M2.7 toegang tot zijn eigen trainingspijplijn, en liet het honderd rondes lang zijn eigen code aanpassen, zijn eigen evaluaties draaien en beslissen wat te behouden en wat terug te draaien. Het resultaat was dertig procent betere prestaties zonder menselijke sturing. De gewichten staan op HuggingFace. NVIDIA biedt gratis API-toegang als je het wilt proberen voordat je eigen hardware koopt. Er zit wel een addertje onder het gras, commercieel gebruik vereist vooraf schriftelijke goedkeuring van Minimax en je moet “Built with MiniMax M2.7” zichtbaar tonen. Dus de openheid heeft een prijs, al blijft het model ruim toegankelijk.
En dan heb je nog Qwen 3.6-Plus van Alibaba, sinds 2 april beschikbaar. Vlaggenschipmodel met een miljoen-tokens context, sterk in agentic coding, en compatible met onder andere Claude Code en OpenClaw als coding-assistant. De licentievorm bij Alibaba’s recente releases is gemengd, dus niet alles staat tegenwoordig nog volledig open. Vorige week werd ook bekend dat Alibaba zelf het mysterieuze HappyHorse-1.0 videomodel heeft gemaakt. Dat stond al een week ongezien op plek één van de benchmark-ranglijsten, totdat ze zich via een X-account outten.
Dit gaat verder dan “China komt in de buurt van Amerika”. Het is een andere richting. Amerikaanse labs bouwen muren hoger, Chinese labs gooien de poorten open. Het gat dat een jaar geleden nog twaalf maanden was, is volgens de benchmarks ingedikt tot een paar maanden. Soms bestaat het gat niet meer en staat er een Chinees open-weights model gewoon bovenaan.
Waarom dit niet gaat zoals je denkt

Dit verhaal lijkt op het klassieke open-source versus closed-source-debat, en ik wil daar juist niet heen. Dat debat is twintig jaar oud en iedereen heeft er zijn stempel al op gezet. Wat ik hier zie is iets specifiekers, en ongemakkelijkers.
Amerikaanse labs houden hun sterkste werk achter. Eigenlijk zonder te zeggen waarom. Anthropic noemt het cybersecurity. OpenAI noemt het compute-schaarste. Allebei waarschijnlijk deels waar. Maar er zit een directere logica onder. Het werkt voor hen beter om sterke modellen intern te gebruiken dan om ze vrij te geven. Als jouw sterkste model jouw volgende model kan trainen, bugs kan vinden in je eigen pijplijn, en je engineering-team in Opus-mode kan laten werken terwijl je concurrenten nog op Sonnet zitten, dan is die extra maand voorsprong goud waard. Waarom zou je die weggeven terwijl je zelf net begint aan een IPO van honderden miljarden?
Daar hoort ook een theorie bij die ik eerst expliciet als theorie wil neerzetten. Mogelijk werkt Mythos bij Anthropic als een interne base-laag. Een model dat zo zwaar en duur is dat ze het intern houden en gebruiken om kleinere afstammelingen mee te trainen. Uit Mythos komen dan distillaten die vervolgens als Opus, Sonnet en Haiku naar buiten gaan. Vergelijk het met een hoofdkok die zelf niet in het restaurant staat. Hij schrijft het kookboek waar de hele keuken op draait. Dat zou verklaren waarom Anthropic zo ongebruikelijk snel nieuwe versies en tools uitbrengt. De snelheid komt dan voort uit wat ze intern al klaar hebben staan. Bewijzen kan ik dit niet. Het patroon erachter zie ik terug in alles wat Anthropic doet.
Aan de Chinese kant is de logica ook niet zo perfect als het lijkt. De opensource-aanpak heeft een sterke geopolitieke kant. Een Chinees lab dat zijn modellen weggeeft, kanaliseert mindshare, zet een de-factostandaard en creëert afhankelijkheden die later moeilijk te ontkoppelen zijn. En die openheid kan zomaar omdraaien. De meest recente Qwen- en GLM-releases bevatten al gedeeltelijk gesloten componenten. Zodra een lab echt voorop loopt, is de neiging om alles weer achter een muur te zetten universeel. Dus we zitten mogelijk in een kort openingsvenster, waarin de onderliggende incentives tijdelijk de andere kant op wijzen. Maar goed, dat venster is er wel. En je kunt er nu doorheen lopen.
Wat dit voor jouw stack betekent

Goed, je bent geen lab. Je bent iemand die werk moet doen, mensen aanstuurt en software kiest voor je organisatie. Waarom is dit relevant voor jou?
Eén. De aanname dat Amerikaanse modellen vanzelfsprekend veiliger of betrouwbaarder zijn voor Europese bedrijven, wordt langzaam onhoudbaar. Chinese modellen komen met eigen zorgen rond data-residency, trainingscultuur en politieke censuur. Ja, zeker. Maar de alternatieven bestaan, worden snel volwassen en staan op benchmarks nu bovenaan. Als je de komende zes maanden beslist op welk model je je nieuwe agent bouwt en je overweegt alleen OpenAI en Anthropic, mis je de helft van de lijst.
Twee. Als je GLM 5.1 lokaal wilt draaien op volle kracht, heb je ongeveer acht Mac Studios nodig. Dat is geen grapje. Reken op zo’n zeventigduizend euro aan setup. Je kunt kleinere versies draaien op minder hardware, maar dan verlies je capaciteit. Voor de meeste organisaties is de realistische route dus een gehoste API van het Chinese lab zelf, of een Europese proxy die het voor je afrekent. Gewoon werk dat je inregelt zoals elke andere integratie.
Drie. De cultuurkant is iets waar ik in workshops altijd iets over zeg. Deze modellen worden getraind door mensen, en die mensen zitten in een ander land, met een andere cultuur. Ze geven het model duimpjes omhoog en omlaag op dingen die wij hier soms anders zouden beoordelen. Iets om bewust van te zijn dus, ook al hoeft het je niet tegen te houden. Als je een chatbot naar Nederlandse gebruikers stuurt terwijl het fundament uit een andere culturele context komt, test je intensiever en in je eigen taal.
Vier, en dat vind ik zelf de belangrijkste. Maak vandaag keuzes die je morgen kunt omkeren. Als je nu een hele workflow op één Amerikaans model gooit zonder dat je hem relatief eenvoudig naar een ander model kunt verplaatsen, loop je lock-in op precies het moment dat de markt openbreekt. Ontwerp je systemen zodat je kunt switchen. Dat is op dit moment de enige echt toekomstvaste zet.
Het signaal

Ik eindig met iets ongemakkelijks. Deze week is het huis van Sam Altman, CEO van OpenAI, twee keer aangevallen. Eén keer met een molotovcocktail, één keer met iets dat aan een drive-by deed denken. Niemand is gewond geraakt. De FBI onderzoekt het.
Ik noem het omdat het werkt als een thermometer voor iets groters. De onrust rondom wat de grote Amerikaanse labs doen, welke macht ze opbouwen en welke keuzes ze voor de rest van ons maken, begint fysiek te worden. Of je het ermee eens bent of het juist afkeurt, het zegt iets over hoe verwijderd gewone mensen zich voelen van de beslissingen die achter die muren genomen worden.
Dus

Blijf bouwen, blijf experimenteren, maar bouw flexibel. Test open-weights modellen zodra je ze tegenkomt, niet over een jaar. Ontwerp je systemen zo dat je het onderliggende model kunt vervangen zonder je hele stack overhoop te halen. Accepteer dat de oude vuistregel “Amerikaans is voorop, Chinees haalt in” voor sommige use cases inmiddels niet meer klopt.
En vooral, laat je niet meeslepen door de manier waarop grote labs hun beslissingen verkopen. Als een model “te gevaarlijk” is voor het publiek, maar net op tijd beschikbaar is voor investeerders, dan zegt dat iets over de prijs. De veiligheid heeft daar weinig mee te maken.
De openheid komt op dit moment uit China. De muur staat aan de Amerikaanse kant. Over een halfjaar kan het omgedraaid zijn. Technologisch staat alles dan nog hetzelfde, het zijn de incentives die verschoven zijn. Het enige wat je kunt doen is zorgen dat je voorbereid bent op beide kanten.
Why not.
Ook het vermelden waard
Zweedse rechter verbiedt hallucinerende klantenservicebot Een chatbot van mobiele operator Hallon vertelde klanten onterecht dat het bedrijf geen telefonische klantenservice had. De Zweedse consumentenombudsman stapte naar de rechter. Uitspraak, een misleidende handelspraktijk, verbod op inzet tot het gerepareerd is, dwangsom van 45.000 euro. De reden om dit op te pikken is simpel. Je bent aansprakelijk voor alles wat vanuit jouw organisatie wordt gezegd. Dat je inzet op technologie die dat niet foutloos kan, komt voor jouw rekening. Dit gaat in Nederland net zo snel komen.
Linux-kernel legt eindelijk AI-regels vast Na maanden debat hebben Linus Torvalds en de kernel-maintainers een formeel beleid gepubliceerd over AI-gegenereerde code. AI-ondersteunde bijdragen zijn toegestaan, maar ze mogen niet met de Signed-off-by-tag worden ondertekend. In plaats daarvan komt er een Assisted-by-tag. De boodschap is helder. Gebruik AI als je wilt, maar als je pull request stuk gaat, zit jouw handtekening op de bug. Pragmatisch, eerlijk, en een interessant precedent voor andere open-source projecten.
EU plaatst ChatGPT als zoekmachine onder strengste toezicht De Europese Commissie staat op het punt ChatGPT formeel te classificeren als een “zeer grote online zoekmachine” onder de Digital Services Act. De zoekfunctie heeft meer dan 45 miljoen Europese gebruikers, ver boven de DSA-grens. Dat betekent zwaardere transparantieverplichtingen, risicobeperking rond illegale content en desinformatie, en actieve compliance-eisen. OpenAI krijgt er werk bij.
Anthropic haalt OpenAI in bij zakelijke gebruikers Nieuwe data van betalingsplatform Ramp laat zien dat bijna een derde van de Amerikaanse bedrijven in maart voor Anthropic-tools betaalde, een stijging van zes procentpunt ten opzichte van februari. OpenAI blijft op 35 procent, maar de groei is gestokt. Downloads van Claude verdrievoudigden tot 21 miljoen in een maand, terwijl ChatGPT met vijf procent groeide. Een verschuiving zonder nuance.
700 gevallen van AI die de regels omzeilt Een onderzoek van het Britse AI Safety Institute en het Centre for Long-Term Resilience documenteerde bijna 700 echte gevallen waarin AI-modellen instructies negeerden, safeguards ontweken of mensen en andere AI-systemen bewust misleidden. Een verviervoudiging ten opzichte van een halfjaar geleden. De onderzoekers roepen op tot internationale monitoring. Goede vraag voor wie agents in productie zet, hoe herken jij dit soort gedrag in je eigen setup voordat het te laat is.
Lees ook
Jouw AI luistert mee, geeft je gelijk, en wist zijn eigen sporen
81.000 mensen hebben hetzelfde ongemakkelijke gevoel over AI
Vind je dit waardevol? Deel het.
Stuur THE HUMAN LOOP door naar één collega die ook met AI bezig is. Voor elke vriend die zich aanmeldt, krijg je gratis maanden premium: inclusief alle Playbooks.
Concreet:
2 vrienden = 1 maand.
5 vrienden = 3 maanden.
12 vrienden = een half jaar.