

Het WAINUT Framework. Van een goede prompt naar goed resultaat.
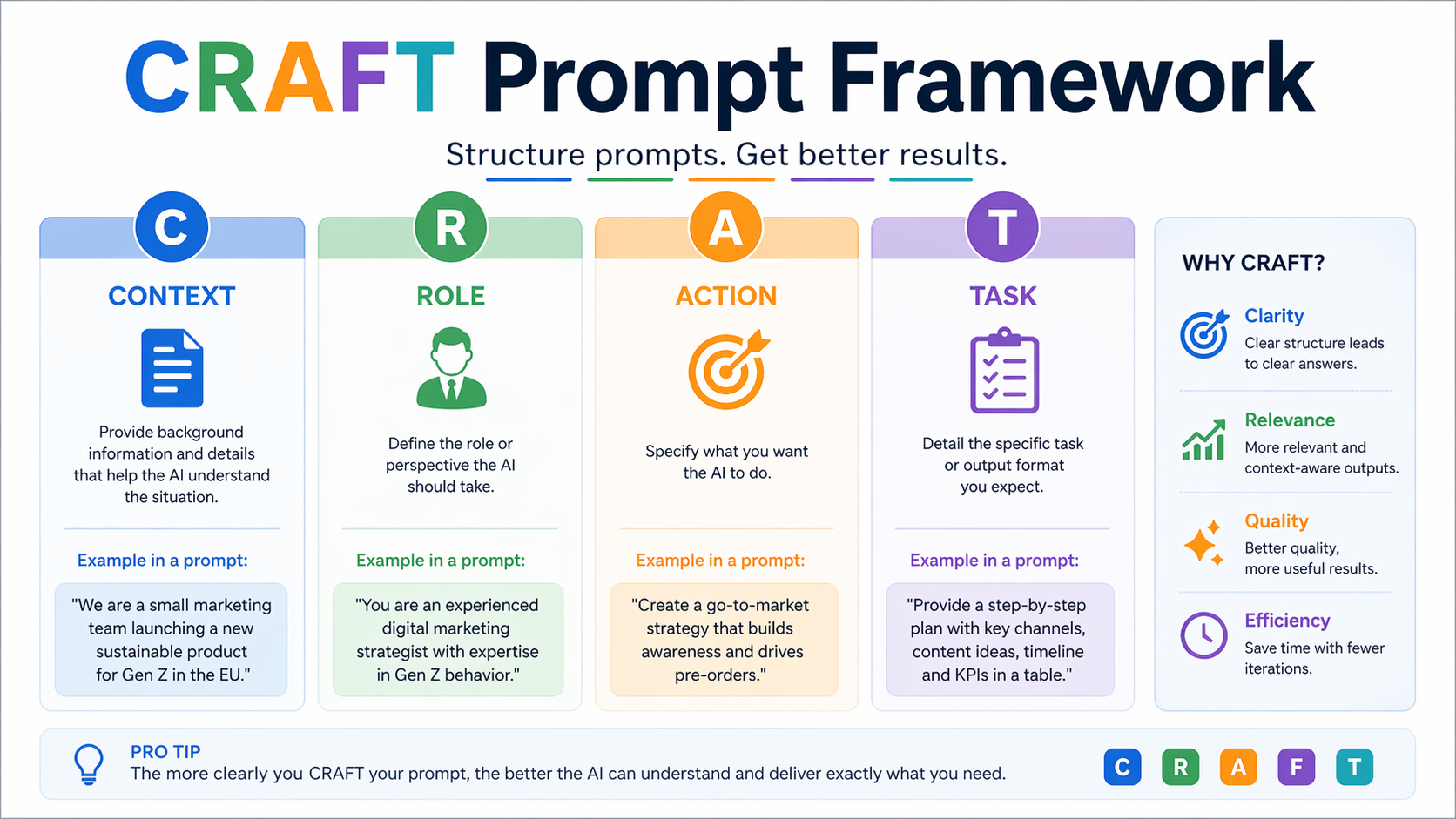
CRAFT leert je een goede prompt schrijven. WAINUT leert je goed werken met AI. Het verschil is groter dan je denkt.


Je kent het vast. Je typt een keurige prompt in ChatGPT. Rol, context, taak, alles zit erin. En dan krijg je iets terug dat... oke is. Niet fout. Maar ook niet wat je nodig had. Je probeert het opnieuw. Iets meer context. Iets andere formulering. Het wordt een beetje beter, maar niet genoeg. Na drie pogingen geef je het op en schrijf je het zelf.
Dat is geen toeval. Een goede prompt is namelijk slechts één stap in een heel werkproces.
Het gat dat niemand ziet
In de afgelopen maanden heb ik tientallen AI-trainingen gegeven. Verzekeraars, gemeenten, uitzendbureaus, bouwbedrijven. Overal leren teams CRAFT of een variant ervan: Context, Role, Action, Task. Ze schrijven keurig gestructureerde prompts. En bij simpele taken werkt dat prima. Een mail samenvatten? Keurig. Een vergadering voorbereiden? Gaat goed.
Maar zodra het echte werk begint, lopen ze vast.
Een team wilde twee pensioenfondsdocumenten van 80 pagina’s inhoudelijk vergelijken. De prompt was netjes opgebouwd volgens CRAFT: rol (”je bent een pensioenanalist”), context (twee PDF’s bijgevoegd), taak (”vergelijk deze documenten”). Prima prompt. Niks mis mee.
Het resultaat? Een oppervlakkige vergelijking die de helft miste. Geen gestructureerde categorieën. Geen onderscheid tussen harde feiten en interpretaties. Copilot kreeg 160 pagina’s zonder structuur en moest zelf uitzoeken wat “vergelijken” betekent.
Eigenlijk is dat logisch.
Denk aan bowlen. CRAFT leert je de bal richten. De boog, de snelheid, het doel. Maar het zet geen hekjes omhoog. En als je zonder hekjes gooit met een complex document van 80 pagina’s, dan rolt die bal zo de goot in.
Dat is het gat dat ik steeds weer zie. Het werkproces rondom de prompt ontbreekt. De voorbereiding. De afbakening. De controle achteraf. CRAFT dekt één stap. Het echte werk zit in alles eromheen.
Van prompt-framework naar werkframework
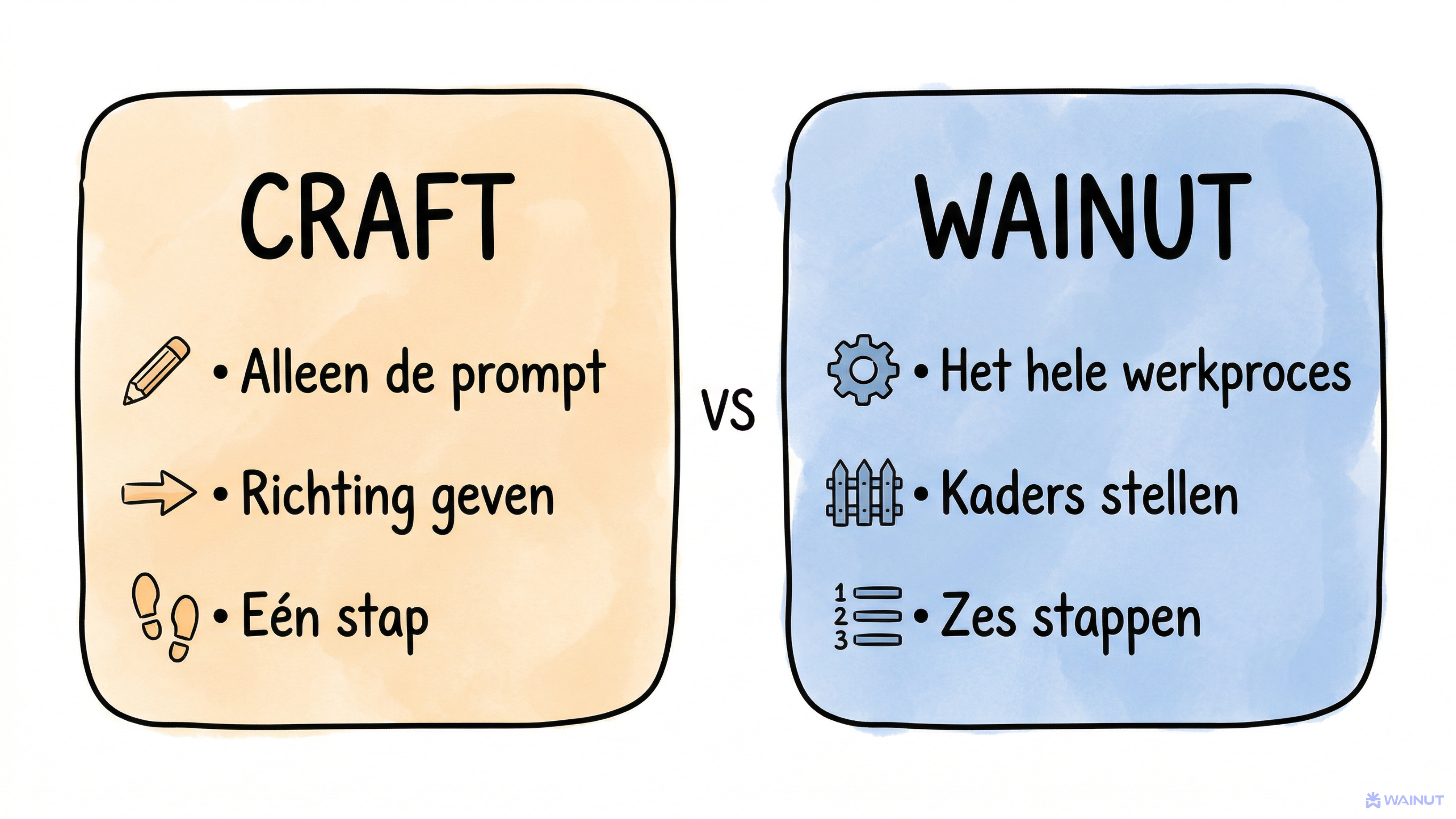
WAINUT staat voor zes stappen die je hele werkproces met AI dekken. Je kunt het vergelijken met Plan/Do/Check, het principe dat in elke organisatie bekend is.
En daar zit de sleutel. Ik zeg het in elke training: stel je voor dat elke taak drie fases heeft. Analyseren, uitvoeren, controleren. AI is steeds beter in de uitvoerfase: code schrijven, tekst genereren, projectplannen maken. Maar ik zie dat de uitvoerfase juist minder belangrijk wordt, en de fases ervoor en erna belangrijker. Je tijd verschuift van doen naar denken en controleren.
WAINUT pakt alle drie de fases.
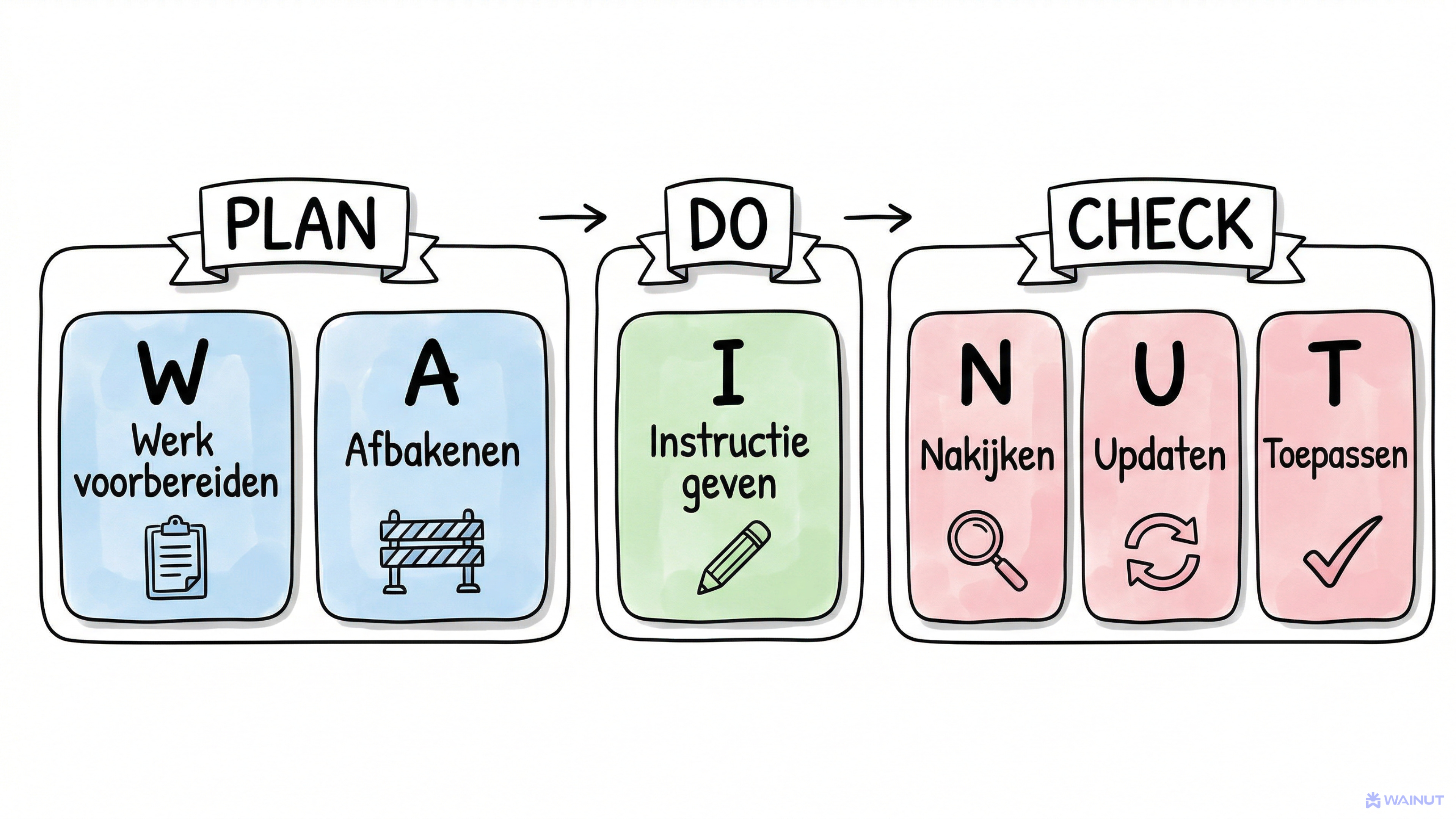
PLAN
W = Werk voorbereiden
Dit is de stap die iedereen overslaat. En het is de stap waar 80% van je resultaat wordt bepaald.
Werk voorbereiden betekent vier dingen:
Materiaal. Wat moet het model zien, in welke vorm? 80 pagina’s rauw erin gooien werkt niet. Laat eerst per document apart een samenvatting maken op dezelfde structuur. Knip grote bestanden op. Zorg dat het model kan vergelijken door de informatie vergelijkbaar aan te bieden.
Stijl. Welke toon, welk design, welk format? Moet het een tabel worden, bullet points, een rapport? In welke taal? Formeel of informeel? Gericht op het managementteam of op uitvoerende medewerkers?
Stappen. Wat is de logische volgorde? Stap 1 is analyse, stap 2 is vergelijking, stap 3 is conclusie. Niet alles tegelijk, maar opgebouwd. Hoe minder stappen AI autonoom moet zetten, hoe betrouwbaarder het resultaat. Het is net als een estafette. Bij elke wissel kan de stok vallen.
Rol. Welke rol geef je het model? Niet alleen "je bent een analist" (dat is CRAFT). Is dit een coördinator die meerdere stappen aanstuurt? Een schrijver? Een kritische reviewer? De rol bepaalt hoe het model de taak aanpakt.
Kijk er zo naar. als je een nieuwe collega een complexe opdracht geeft, begin je ook niet met “vergelijk deze twee rapporten.” Je zegt: “Hier zijn twee rapporten. Lees ze allebei. Maak voor elk rapport een samenvatting op deze vier punten. Leg die samenvattingen naast elkaar. En markeer waar ze van elkaar afwijken.” Dat is W.
A = Afbakenen
Dit zijn je hekjes. De rails bij het bowlen. Zonder afbakening kan het model alle kanten op, en dat doet het ook.
Grenzen. Wat mag niet? Geen meningen, alleen feiten uit de documenten. Niet meer dan 2 pagina’s output. Geen informatie van het internet, alleen uit de bijgevoegde bestanden.
Scope. Hoeveel in één keer? Eén document per gesprek of meerdere? Eén vraag per prompt of een reeks? Hoe minder het model tegelijk hoeft te doen, hoe betrouwbaarder.
Bronnen. Welke documenten, welke data? Expliciet benoemen wat het model mag gebruiken en wat niet. “Gebruik alleen het jaarverslag 2025 en de klanttevredenheidsenquête.”
Stopmoment. Wanneer moet het model stoppen en terugvragen? “Als je informatie mist die je nodig hebt, vraag het dan in plaats van te gokken.” Dit is cruciaal. AI weigert nooit een opdracht. Het levert altijd iets op. Maar een antwoord is niet hetzelfde als het juiste antwoord. Door een stopmoment in te bouwen dwing je het model om eerlijk te zijn over wat het niet weet.
DO
I = Instructie geven
Hier schrijf je de prompt. En hier past CRAFT prima in. Context, rol, actie, taak. Niets mis mee als instrument. Maar het is stap 3 van 6.
Het verschil: zonder W en A is je prompt een wens. Met W en A is het een opdracht. “Vergelijk deze documenten” versus “Vergelijk deze twee samenvattingen op deze vijf categorieën, output als tabel, maximaal 2 pagina’s, markeer waar bronnen tegenstrijdig zijn.” Dezelfde vraag. Compleet ander resultaat.
CHECK
N = Nakijken
Dit is waar de meeste tijdwinst zit. Of de meeste tijdverspilling. Dat hangt af van één beslissing.
Nakijken betekent twee dingen. Ten eerste: check de output tegen de bron. Klopt wat er staat? Mist er iets? Zijn er beweringen die je niet kunt terugvinden in het originele document?
Ten tweede, en dit is het belangrijkste: scoor de output. Is dit 80% of meer van wat je nodig hebt? Of is het 60%?
De 60/80-regel. Als je output op 60% zit (het gaat de goede kant op, maar het is niet bruikbaar), dan ga je niet oppoetsen. Je gooit het weg en gaat terug naar W. Meer context, betere voorbereiding, andere afbakening, opnieuw.
Waarom? Omdat een 60%-output nooit naar 100% te verfijnen is. Je kunt een slechte basis niet oppoetsen tot een goed resultaat. Dat is de grootste tijdverspiller die ik zie bij teams: ze zitten vijf ronden te herschrijven op een uitkomst die fundamenteel niet deugt.
Terug naar de bowling: als de bal in de goot ligt, ga je hem niet halverwege bijduwen. Je pakt een nieuwe bal, stelt je anders op, en gooit opnieuw.
Maar als je output op 80-90% zit? Dan werkt verfijnen wel. Dan zit je in de goede richting en kun je met kleine aanpassingen naar het gewenste resultaat.
De loop is dus:
W → A → I → N → 80%+? → U → T
Of:
W → A → I → N → Onder 80%? → Terug naar W
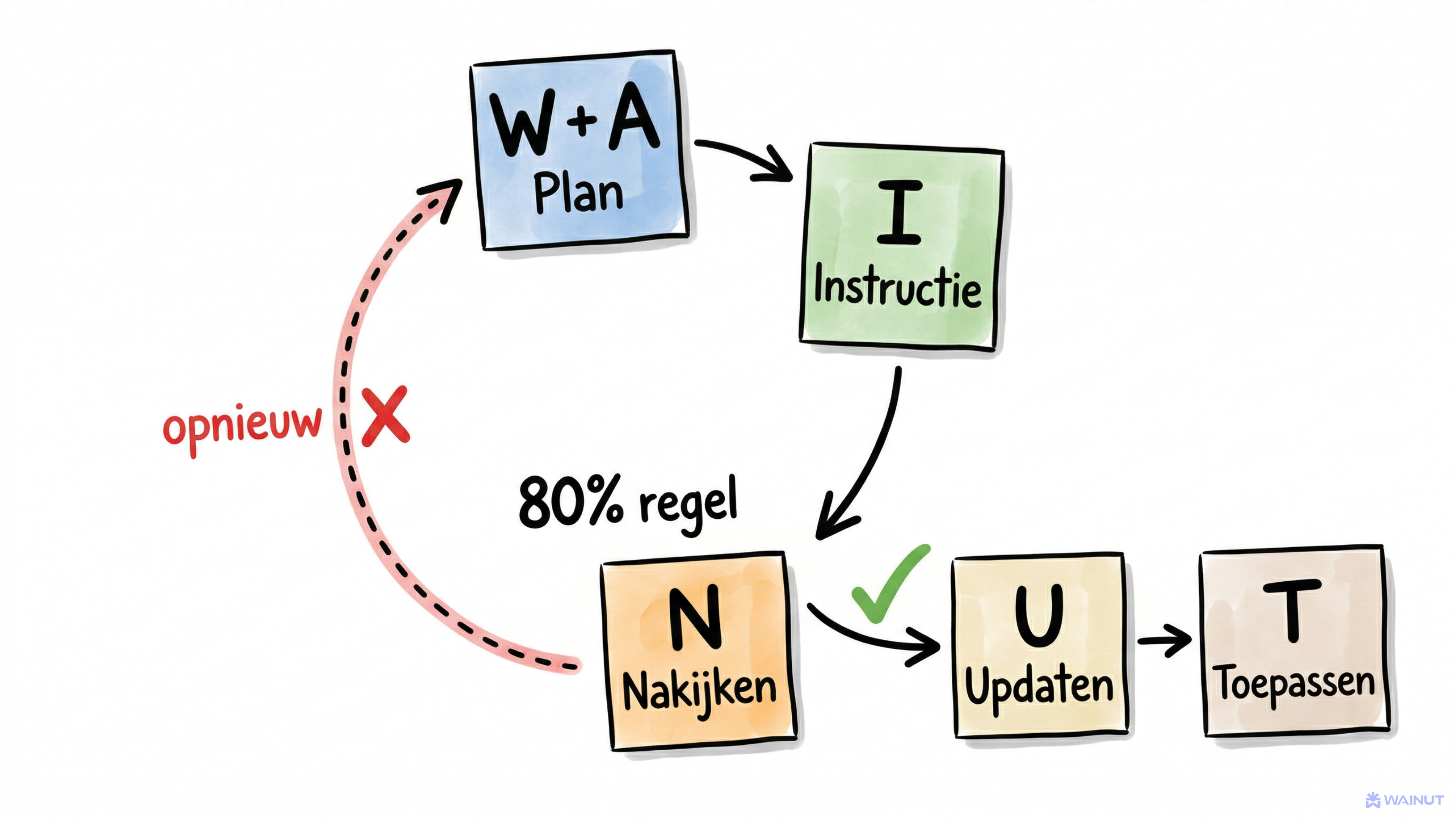
Dat ene beslismoment bij N is het verschil tussen productief werken met AI en urenlang ronddraaien.
U = Updaten
Alleen als je op 80% of hoger zit. Dan bijsturen en aanscherpen. “Je mist de categorie nabestaandenpensioen, voeg toe.” Of: “De kosten kloppen niet voor fonds B, check pagina 34.” Of: “Maak de toon formeler, dit gaat naar het managementteam.”
Verfijnen is een gesprek. Stap voor stap werk je naar het gewenste resultaat.
T = Toepassen
De stap die wegvalt zodra je tevreden bent met het antwoord. Wat doe je met de output? Kopieer je het naar Word? Deel je het met je team? Sla je het op als template voor de volgende keer?
T dwingt je om na te denken over de landing. Niet alleen: ik heb een antwoord. Maar: ik heb een bruikbaar resultaat dat ik kan toepassen in mijn werk. En misschien nog belangrijker: ik heb een werkwijze die ik de volgende keer weer kan gebruiken.
Waarom dit werkt
De kracht van WAINUT zit in de verdeling.
In Plan/Do/Check termen:
Plan = W + A. Dit is mensenwerk. Hier zit je vakkennis. AI kan je helpen met de uitvoering, maar de vraag “wat moet er geanalyseerd worden en binnen welke kaders” is jouw expertise.
Do = I. Het model voert uit. Dit wordt steeds meer AI. Over twee jaar is dit het makkelijkste deel van het proces.
Check = N + U + T. Weer mensenwerk. Hier zit je oordeel.
En dat is de boodschap die ik in elke training geef. Jullie worden juist belangrijker door AI. Want de Do-fase is straks geautomatiseerd. Het verschil tussen een goed en een waardeloos resultaat zit in hoe je plant en hoe je checkt. Dat is jullie vak.
CRAFT leeft alleen in de Do-fase. Daarom voelt het beperkt zodra de taak complex wordt. Het helpt je typen. Het denkwerk blijft bij jou.
Het bewijs is ‘‘De Muur’’
In mijn trainingen gebruik ik een oefening die ik “De Muur” noem. Deelnemers krijgen een complexe maar realistische opdracht. Een e-mailketen over een IT-migratieproject. Zes mails, vier mensen, twee in CC. Vol verborgen valkuilen.
Eerste ronde: gooi het direct in Copilot. “Maak een projectplan.” Het resultaat ziet er professioneel uit. Strakke koppen, nette opsomming, deadlines. Maar als ik zes controlevragen stel, scoren teams gemiddeld 0 tot 1 uit 6. Gehalluceerde verantwoordelijken. Genegeerde deadlines. Voorwaardelijke toezeggingen die als harde afspraken worden gepresenteerd.
Dat is die 60%-output. Het ziet er goed uit, maar het deugt niet.
Tweede ronde: dezelfde opdracht, maar nu via WAINUT.
W: laat eerst per mail analyseren wie wat zegt, welke beloften er gedaan zijn, welke vragen open staan. A: “Markeer alles wat onbevestigd of tegenstrijdig is. Geen aannames. Als informatie ontbreekt, zeg dat.” I: pas daarna de prompt voor het projectplan. N: check het plan tegen de originele mails.
Het resultaat ziet er minder gelikt uit. Items staan gemarkeerd als “onbevestigd.” Tegenstrijdige deadlines worden benoemd. Verantwoordelijkheden die niet expliciet zijn toegewezen, worden niet verzonnen. Minder mooi, maar dramatisch betrouwbaarder.
Dat is het verschil tussen richting geven en kaders stellen.
Terug naar het voorbeeld
Datzelfde team met de twee pensioenfondsdocumenten deed de opdracht opnieuw via WAINUT:
W = Beide documenten apart uploaden. Per document eerst een samenvatting laten maken op dezelfde structuur: dekkingen, kosten, uitsluitingen, voorwaarden, doelgroep, nabestaandenpensioen. Twee keer dezelfde structuur. Nu heeft het model iets om naast elkaar te leggen.
A = “Vergelijk alleen op deze zes categorieën. Output als tabel. Per verschil: wat zegt fonds A, wat zegt fonds B, wat is het effect voor de deelnemer. Geen meningen, alleen feiten uit de documenten.”
I = “Maak een vergelijkingstabel van pensioenfonds A en B die ik kan gebruiken om een advies voor te bereiden.”
N = Drie rijen uit de tabel gecheckt tegen de originele documenten. Klopte. Score: 85%.
U = “Je mist de categorie nabestaandenpensioen. Voeg toe. En de kosten kloppen niet voor fonds B, check pagina 34.”
T = Vergelijkingstabel opgenomen in het adviesrapport. Prompt opgeslagen als template voor toekomstige vergelijkingen.
Zonder de W lever je een onmogelijke opdracht. Je vraagt iemand twee boeken te vergelijken door ze allebei tegelijk open op tafel te leggen. Dat doet een mens ook niet. Je maakt eerst aantekeningen per boek, dan vergelijk je de aantekeningen.
Onthoud
CRAFT is één stap (de I). WAINUT dekt het hele proces. Jouw waarde als professional zit links en rechts. In hoe je plant en hoe je checkt.
Begin deze week met één complexe taak die je normaal direct in AI gooit. Loop de zes letters door. Ervaar het verschil.
Je hebt hierboven over het framework gelezen. Hieronder staat hoe je het in de praktijk brengt: de complete checklist per letter die je kunt printen, vijf uitgewerkte voorbeelden voor verschillende rollen, de zeven fouten die ik het vaakst zie, en pro tips uit mijn trainingen.
Nog geen abonnee? Je eerste framework is gratis. Of deel The Human Loop met een collega en krijg gratis maanden cadeau.
